workqueue驱动的底半部实现方式之一就是工作队列,作为内核的标准模块,它的使用接口也非常简单,schedule_work或者指定派生到哪个cpu的schedule_work_on。
还有部分场景会使用自定义的workqueue,这种情况会直接调用queue_work和queue_work_on接口。
static inline bool schedule_work_on(int cpu, struct work_struct *work)
{
return queue_work_on(cpu, system_wq, work); //workqueue_struct使用通用的system_wq
}虽然使用起来简单,但其实内核内部的整个workqueue框架还是比较复杂的。
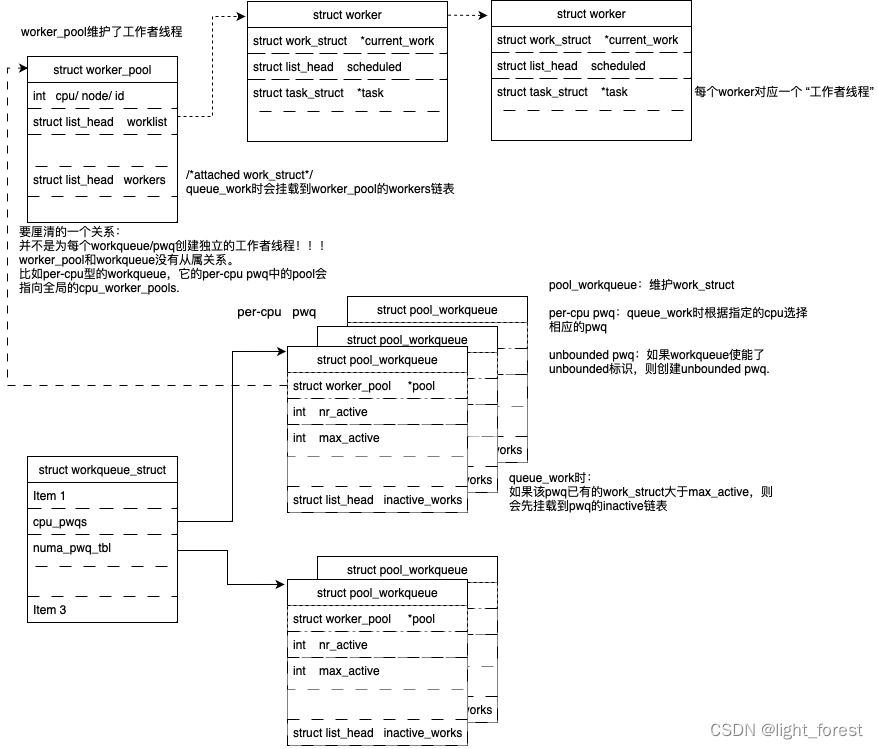
后面摘录一些关键性的代码,辅助理解上面的框架:
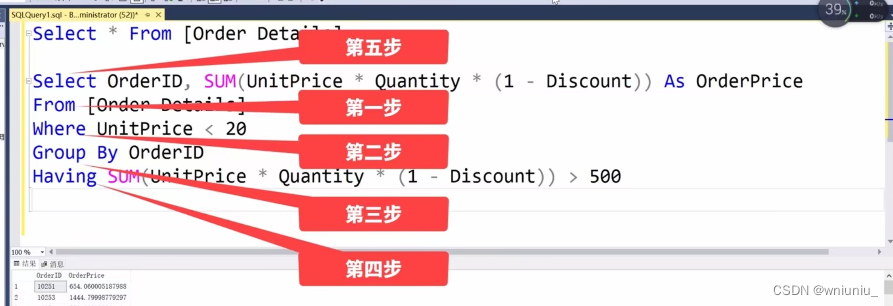
1、queue_work接口如何选择pwq
如果workqueue使能了WQ_UNBOUND标识,则根据当前cpu选择一个numa node。unbounded pwq是已numa node来划分的。
如果是普通的workqueue,则按照用户指定的cpu(没有指定则使用当前cpu)找到相应的pwq。
/* pwq which will be used unless @work is executing elsewhere */
if (wq->flags & WQ_UNBOUND) {
if (req_cpu == WORK_CPU_UNBOUND)
cpu = wq_select_unbound_cpu(raw_smp_processor_id());
pwq = unbound_pwq_by_node(wq, cpu_to_node(cpu));
} else {
if (req_cpu == WORK_CPU_UNBOUND)
cpu = raw_smp_processor_id();
pwq = per_cpu_ptr(wq->cpu_pwqs, cpu);
}2、queue work时work struct挂载到哪个队列
1)当前pwq里pending的任务数量不多,直接挂载到worker pool的任务链表等待执行
2)pending的任务大于pwq的最大活跃数,先挂载到pwq的inactive_works链表;
if (likely(pwq->nr_active < pwq->max_active)) {
trace_workqueue_activate_work(work);
pwq->nr_active++;
worklist = &pwq->pool->worklist; //pending任务不多,直接挂载到worker pool的任务链表等待执行
if (list_empty(worklist))
pwq->pool->watchdog_ts = jiffies;
} else {
work_flags |= WORK_STRUCT_INACTIVE;
worklist = &pwq->inactive_works; //pending的任务大于最大活跃数,则挂载到pwq的inactive_works链表;
}2、初始化pwq的worker_pool
alloc workqueue时,如何指定worker_pool?
1)per-cpu pwq和per-cpu worker pool
如果没有使能WQ_UNBOUND标识,则申请per-cpu pwqs,链接到per-cpu work_pools。
注意1:并不是为每个workqueue/pwq新创建了worker_pool。不管创建多少workqueue,他们指向的都是一组worker_pool。
那有人可能会想,如果有很多工作队列,只有一组worker_pool忙得过来吗?
其实worker_pool定义的是相同属性的一类工作者线程,比如工作在哪个cpu上/以哪个优先级运行/绑定哪个numa(unbounded绑定numa)。worker_pool中链表维护的worker才对应单个工作者线程。worker thread运行期间会根据当前的忙闲动态创删新的worker,动态启动和停止新的worker thread。
注意2:对于per-cpu worker_pool来说,每个cpu其实对应两个worker_pool,分别是highpri和lowpri,nice值分别为-20和0。实际配置给pwq的是高优先级worker_pool。
static int alloc_and_link_pwqs(struct workqueue_struct *wq)
{
if (!(wq->flags & WQ_UNBOUND)) {
wq->cpu_pwqs = alloc_percpu(struct pool_workqueue); //per_cpu pwq
if (!wq->cpu_pwqs)
return -ENOMEM;
for_each_possible_cpu(cpu) {
struct pool_workqueue *pwq =
per_cpu_ptr(wq->cpu_pwqs, cpu);
struct worker_pool *cpu_pools = //从cpu_worker_pools找到worker_pool
per_cpu(cpu_worker_pools, cpu);
init_pwq(pwq, wq, &cpu_pools[highpri]); //链接到高优先级的worker_pool
mutex_lock(&wq->mutex);
link_pwq(pwq);
mutex_unlock(&wq->mutex);
}
return 0;
}
/* 申请unbouned pwq*/
}2)unbounded pwq和unbounded worker pool
使能了WQ_UNBOUND标识,则分配unbounded pwq。并从全局unbound_pool_hash中找到一个attrs属性指定的work_pool,如果没有会新建一个,将这个worker_pool配置给pwq。
alloc_and_link_pwqs //先申请per cpu pwq,后申请unbounded pwq
--->apply_workqueue_attrs
--->apply_wqattrs_prepare
--->alloc_unbound_pwq
static struct pool_workqueue *alloc_unbound_pwq(struct workqueue_struct *wq,
const struct workqueue_attrs *attrs)
{
struct worker_pool *pool;
struct pool_workqueue *pwq;
lockdep_assert_held(&wq_pool_mutex);
pool = get_unbound_pool(attrs); //找到相同attrs属性的worker_pool,没有则新建一个
if (!pool)
return NULL;
pwq = kmem_cache_alloc_node(pwq_cache, GFP_KERNEL, pool->node);
if (!pwq) {
put_unbound_pool(pool);
return NULL;
}
init_pwq(pwq, wq, pool); //pwq->pool = pool
return pwq;
}3、创建worker pool
1)per cpu的worker pool
per cpu的worker pool是一个全局性的初始化,在workqueue_init_early接口中实现。这明显是kernel_init启动过程中调用的初始化接口。
void __init workqueue_init_early(void)
{
/* initialize CPU pools */
for_each_possible_cpu(cpu) {
struct worker_pool *pool;
i = 0;
for_each_cpu_worker_pool(pool, cpu) { //遍历每个worker pool
BUG_ON(init_worker_pool(pool)); //初始化worker pool
pool->cpu = cpu;
cpumask_copy(pool->attrs->cpumask, cpumask_of(cpu));
pool->attrs->nice = std_nice[i++];
pool->node = cpu_to_node(cpu);
/* alloc pool ID */
mutex_lock(&wq_pool_mutex);
BUG_ON(worker_pool_assign_id(pool));
mutex_unlock(&wq_pool_mutex);
}
}
}2)unbounded worker pool
前面讲为pwq链接worker pool的时候提过,unbounded worker pool是根据动态按需分配的。就是在使用的时候,如果已经创建了相同属性的worker pool,则使用;没有则新建一个。
static struct worker_pool *get_unbound_pool(const struct workqueue_attrs *attrs)
{
/* 已有同属性的worker pool,则返回*/
/* nope, create a new one */
pool = kzalloc_node(sizeof(*pool), GFP_KERNEL, target_node); //没有则创建
if (!pool || init_worker_pool(pool) < 0) //初始化worker pool
goto fail;
}4、创建workqueue
通用的创建接口就是alloc_workqueue。
struct workqueue_struct *alloc_workqueue(const char *fmt,
unsigned int flags,
int max_active, ...)
{
--->alloc_and_link_pwqs //申请和初始化pwq,建立pwq和worker pool的链接
}我们用schedule_work时只需要传入work_struct,并没有指定workqueue。是因为内核提供了一些系统级工作队列,开放给用户直接使用。
比如schedule_work就是直接使用了system_wq。这些工作队列也是在workqueue_init_early注册的。
void __init workqueue_init_early(void)
{
system_wq = alloc_workqueue("events", 0, 0);
system_highpri_wq = alloc_workqueue("events_highpri", WQ_HIGHPRI, 0);
system_long_wq = alloc_workqueue("events_long", 0, 0);
system_unbound_wq = alloc_workqueue("events_unbound", WQ_UNBOUND,
WQ_UNBOUND_MAX_ACTIVE);
system_freezable_wq = alloc_workqueue("events_freezable",
WQ_FREEZABLE, 0);
system_power_efficient_wq = alloc_workqueue("events_power_efficient",
WQ_POWER_EFFICIENT, 0);
system_freezable_power_efficient_wq = alloc_workqueue("events_freezable_power_efficient",
WQ_FREEZABLE | WQ_POWER_EFFICIENT,
0);
}我们最常用的是system_wq。内核按需申请了不同类型的workqueue,也有一些位置会专门使用这些workqueue。